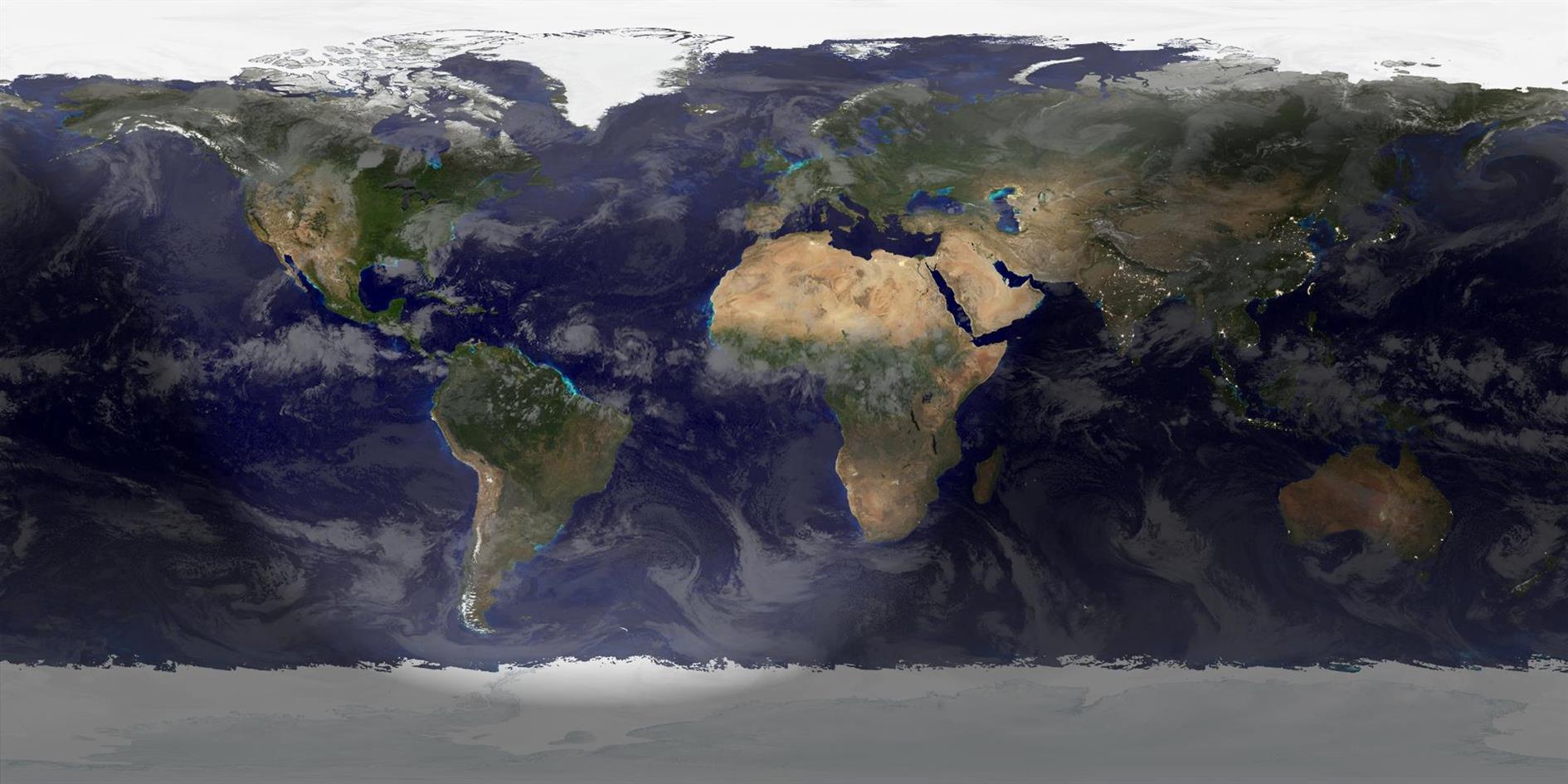
Summer Solstice 2023 is at 14:58 UTC on June 21. The image above shows the exact moment of the Solstice as rendered in Catfood Earth. It's the official if not sartorial start of Summer in the Northern Hemisphere and Winter if you find yourself on the other side of the Equator.
A small town where kids mysteriously vanish. This is quite clever in how the story changes perspective a few times before being resolved.
John Wick 4
Very pretty, but also very flabby.
Knock at the Cabin
Sophie's Choice, set in an Airbnb.
Scream 6
Gory, not clever, not sure why I bothered.
The Last Sentinel
Should have ended: "What did the cats, the horse, the swallows, and Rob do to deserve this?". Reasonably atmospheric in places but ultimately not that good.
The Wandering Earth 2
I very nearly skipped this because the first movie was action trash, like a Chinese take on the indecipherable Transformers movies. The Wandering Earth 2 is a prequel, about dueling visions of how to escape the imminent demise of the Sun. Option 1 is attaching thousands of engines to the Earth and moving it to a different solar system (you can guess this is what ends up happening). Option 2 is digitizing people. It's never made entirely clear where the digitized people would live once the Earth has been engulfed by the Sun, but you're not going to enjoy this movie if you stop to think about any part of it for too long. Like why does a space elevator use rockets? Despite all this it's really good and has the Liu Cixin vibes that I missed from the first film.
TV
Anatomy of a Scandal
Anatomy of a Scandal has shades of the original House of Cards but without the dark humor. It keeps the pace up and the revelations coming, pretty good overall.
Beef
Beef is a Korean-American focused comedy about a parking lot altercation that rapidly spirals out of control. It's outstanding.
Succession Season 4
This ended as well as it could have. Roys, you suck but you will be missed.
(All images included with ITHCWY reviews are the property of their respective owners and are used to illustrate reviews only.)
By Robert Ellison. Updated on Monday, September 29, 2025.
A pleasant loop hike in the Presidio of San Francisco. This is a dog friendly version, many trails are closed to dogs in the spring due to coyote pupping season. It starts at Mountain Lake, winds down the Ecology Trail to the main post and runs past both the new tunnel tops parks before returning to Mountain Lake.
Minnesota just joined the National Popular Vote Interstate Compact, bringing us 10 Electoral College votes closer to not being governed by Presidents with a minority of the popular vote. If your state isn't there yet then do something!
(Published to the Fediverse as:
10 Electoral College Votes Closer #politics#npvic#election The National Popular Vote Interstate Compact is 10 Electoral Votes closer to reality after Minnesota signs up.)
Exactly what you'd expect. Fairly funny mostly good spirited quest adventure that is over-reliant on one gizmo that makes this more like Portal: The Movie.
M3gan
It was clearly the weekend for AI children. After The Artifice Girl I decided I needed to watch M3gan, a horror take on the same sort of topic. The Artifice Girl is thoughtful and quietly disturbing, M3gan has a traditional horror vibe and explores the topic of turning childcare over to technology a little bit before just jumping to killing people. The robot is very very creepy which is good but also you wonder why anyone would trust the thing in the first place.
Polite Socity
Polite Society is a pleasantly bonkers tale of a girl trying to save her sister from a semi-arranged marriage in a British Pakistani community.
The Artifice Girl
The Artifice Girl looks like a three act play turned into a movie. It follows the evolution of an AI girl who was accidentally developed to ensnare online predators. The first act is hugely compelling and the second two can't quite hit the same level, but it's definitely worth watching.
Music
Where's My Love
I wonder how much of the rise in depression can be chalked up to this one painful but beautiful SYML track? It's melancholy just listening but the video provides maximum bleakness.
Podcasts
I'm Not a Monster Series 1
I listened to this the wrong way round, starting with the second series on Shamima Begum. The first is the story of Sam Sally and probably due to having listened to the second series so recently it failed to grab my attention in the same way. It's not exactly the same story, but just how many women ran off to join Islamic State only to discover it wasn't a super empowering society?
The Coldest Case in Laramie
There really should be some naming convention for investigative podcasts that indicates if the case was cracked or not. This is one of the many disappointments that leaves you none the wiser. The highlight is some real insight into just how manipulative the police can be when forcing a confession. Regardless of the crime or level of guilt you really want a lawyer in the room with you.
The Political Party
For UK politics The Political Party has got the goods. Matt Forde interviews anyone who is anybody and quite a few fascinating people who aren't. Even though his politics are not subtle he draws great stories and insights from across the political spectrum. The live shows usually start with some stand-up as well. One of my favorite shows each week.
TV
Mrs. Davis
In Mrs. Davis a nun tries to kill a powerful Artificial Intelligence. This involves finding the Holy Grail and at one point the Grail is in a sperm whale. I really wanted to like it, and while it started off well it got somehow worse with each episode and the whimsy outweighed anything else that might have been going on. Not worth the time.
Perry Mason Season 2
I never watched the original, but Perry Mason on HBO is a fun trip to an alternative reality LA in the 30's.
Star Trek Picard Season 3
For Season 3 Picard stops showing us retirement projects and reunites the crew of Star Trek Next Generation to fight the Borg and some Shapeshifters in a cunning plan to overthrow The Federation that somehow only affects The Youth. I'm all for it. This was the Star Trek cast that probably had the best chemistry and it's amazing to see them together again. The plot just takes a very long time to get going and the final battle involves thousands of starfleet ships that can't quite overpower one aged space dock. Worth it for some quality Worf and Data lines though.
The Bay Season 4
The Bay, from ITV via Britbox in the US is a police procedural set in Morecambe Bay. Although it centers around the family liaison officer it's still a very standard but entertaining whodunit.
The Night Agent
I wasn't expecting too much from The Night Agent. It presents as a formulaic network FBI drama, but its sense of humour is far darker and it has a real edge to it. Based on a book so I'm going to go out on a limb and say any future seasons will be trash.
(All images included with ITHCWY reviews are the property of their respective owners and are used to illustrate reviews only.)
"An antimeme is an idea with self-censoring properties; an idea which, by its intrinsic nature, discourages or prevents people from spreading it."
Important antimemes in my life are other parent's names and all of the fucking single use apps I'm plagued with. My kids in particular have at least one app for every aspect of their lives.
Let's say I need to know where a soccer game is. The location is hidden in an app, and for the life of me I can't remember which one.
Eventually I remember it's LeagueApps, because TeamSnap is the other kid due to some San Francisco soccer schism on a par with what material to put on the pitch (I had to vote on TWO ballot measures on this subject).
Feeling inordinately proud of myself and like I have a few years left before 24-hour nursing care I search my phone for LeagueApps and it's NOT FUCKING THERE. Because they called the app 'Play'. Not LeagueApps Play, just Play.
App developers, if you're not Gmail how about including a little more context? Like 'LeagueApps Play - where is the soccer game?' or 'Toddle - your kids homework' or 'Procare - did you remember to sign your kid in'.
They won't, but next time I'm looking I'll at least be able to Google this post.
(Published to the Fediverse as:
Give your stupid niche kids app a useful name please! #etc#apps If I'm not using it every day, I need help ever finding it again. Please don't get too cute with the name.)
In 1994 Prince Charles promised to be a defender of faith rather than the faith. The BBC has some disturbing news on his coronation plans:
"Despite changes designed to reflect other faiths, the three oaths the King will take and form the heart of the service remain unchanged, including the promise to maintain "the Protestant Reformed Religion"
Less than half of the UK now claim to be Christian. An established religion is as much of an embarrassing relic as the monarchy itself. This is disappointing, but the shocker is that we're being asked to pledge allegiance:
"The order of service will read: "All who so desire, in the Abbey, and elsewhere, say together: I swear that I will pay true allegiance to Your Majesty, and to your heirs and successors according to law. So help me God."
Modern democracy or Game of Thrones? I personally refuse to bend the fucking knee. At least with his mother there was a polite pretense that the allegiance worked the other way round.



















![[ ]](/image.axd?picture=--.png)



