Great Blue Heron at Crissy Field
By Robert Ellison. Updated on Saturday, June 7, 2025.

360 degree 4K timelapse of San Bruno Mountain in San Mateo County, California.
(Published to the Fediverse as: San Bruno Mountain 360 4K #timelapse #360 #4k #video 360 degree 4K resolution timelapse from San Bruno Mountain in San Mateo County, California )
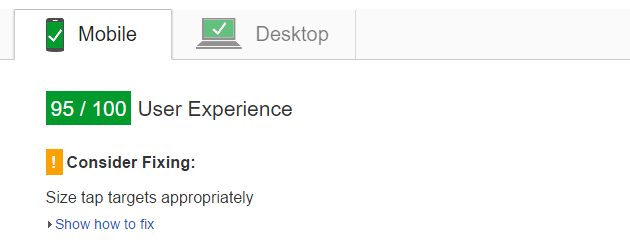
Here's a quick script to automatically monitor your Google PageSpeed Insights desktop and mobile scores for a web page, together with core web vitals (LCP, INP and CLS):
You need a spreadsheet with a tab called results and an API key for PageSpeed Insights and the CrUX API (activate the APIs in the console and create an API key for them, the browser based / JavaScript option). Paste the code above into the script editor for the spreadsheet and add your API key and URLs to monitor. Then just choose triggers from the Resources menu and schedule the monitor function to run once per day.
The script will log the overall PageSpeed score out of 100 for the monitored page. It also logs 75th percentile origin level core web vitals (largest contentful paint (LCP, seconds), interaction to next paint (INP, seconds) and cumulative layout shift (CLS, percent)). If your origin does not have enough data the metric will be omitted. You can change from origin to page level web vitals if you have enough data, just change originLoadingExperience to loadingExperience for PageSpeed Insights and origin to url in the CrUX call.
The results are repeated for desktop and mobile, so your spreadsheet header should be Desktop PSI, Desktop LCP, Desktop INP, Desktop CLS, Mobile PSI, Mobile LCP, Mobile INP, Mobile CLS.
There are a lot of other values returned that you could choose to monitor as well. It would also be easy to extend this to monitor more URLs, or to send you an email if the score drops below a threshold.
Updated May 5, 2019 to use version 5 of the PageSpeed API.
Updated June 13, 2021 to include core web vitals.
Updated October 18, 2025 to use CrUX instead of PageSpeed for core web vitals (Google is removing web vitals from PageSpeed). CrUX might not have device level data for your origin and so the script will now report total aggregate data for both devices if this is the case. I ignore tablet, easy to add if you want it.
(Published to the Fediverse as: Automate Google PageSpeed Insights and Core Web Vitals (CrUX) Logging with Apps Script #code #google #appsscript #gas #pagespeed How to automatically monitor page load performance using the Google PageSpeed Insights API and Apps Script )
Alexander Reben is automatically generating all possible prior art. Which will probably take a while.
Instead, why not stop examining patents altogether?
(via Boing Boing)

Panoramic photo of the full extent of Golden Gate Park as seen from Grand View Park in San Francisco.
(Published to the Fediverse as: Golden Gate Park from Grand View Park #photo #grandview #goldengatepark #sanfrancisco Photo (Panoramic) of Golden Gate Park from Grand View Park in San Francisco, California. )

The April 6 issue of New Scientist has a special focus on immigration. All worth a read, but here's an assessment of the horrible cost:
"A meta-analysis of several independent mathematical models suggests it would increase world GDP by between 50 and 150 per cent. “There appear to be trillion-dollar bills on the sidewalk” if we lift restrictions on emigration, says Michael Clemens at the Center for Global Development, a think tank in Washington DC, who did the research."
And the uncontrollable hordes:
"Niger is next to Nigeria, Nigeria is six times richer and there are no border controls, but Niger is not depopulated. Sweden is six times richer than Romania, the EU permits free movement, but Romania is not depopulated."
Time for open immigration?

Less than half of Americans have passports compared to around 75% in the UK. Brits often use this statistic to mock Americans for being uncurious provincial stay-at-homes.
I've always felt this was unfair though. As an American you might have visited all 50 states, all of the National Parks and maybe thrown in Canada, Mexico and Puerto Rico without having ever bothered with a fully fledged passport.
A Brit on the other hand might have spent a few days eating fish and chips at a British pub in Benidorm and is suddenly a sophisticated world traveler. I don't think so. There is simply more to see and experience in the US without needing to cross a border.
After I moved to America I realized that maybe there was another reason. Americans for some reason don't bother taking vacations. You get massively less vacation time over here and even then a huge number of people don't even manage to take off their paltry few days. There is no effective way to have a holiday overseas if you never take a holiday.
Now I realize that neither of these factors is as important as the United States Postal Service if you have a kid.
In the UK to get a passport you mail in an application and get back a passport. It's pretty easy. Even for children.
In the US you need to go to a Passport Acceptance Facility and that probably means a post office. There is a handy website that lists the 10 closest facilities together with their phone numbers so you can call to make an appointment. These phone numbers are not answered. It's less like a basic government service and more like trying to bag a ticket to Glastonbury.
I gave up and delegated to Fancy Hands (a personal assistant service). They have spent two days on the phone trying and failing to get an appointment.
I was going to do my best to vote my principles this year but at this point any presidential candidate who would force USPS to put in a web scheduling system might just get my vote.
Updated 2016-04-18 23:23:
After I posted this a friend pointed me at the United States Digital Service (via this Ted Video) and basically said why bitch and moan when you could help fix it. Which I don't have a great answer to. Except this.
(Published to the Fediverse as: The real reason Americans don't have passports #etc #passport #travel #usps Americans don't get enough vacation and have plenty to see at home, but the real reason they don't have passports is the United States Postal Service )

Dramatic clouds over the Farallon Islands in the Pacific just off San Francisco.
(Published to the Fediverse as: Clouds Over The Farallones #photo #farallones #farallon #sanfrancisco Photo of some dramatic clouds over the Farallon Islands in the Pacific Ocean near San Francisco, California. )

2/5
I found it hard to care for anyone in this book. Pedestrian mystery.

3/5
Getting into diminishing returns here. Good, but not Silo/Sand good.

3/5

A mosaic timelapse looking over the Pacific from West Portal, San Francisco (a simultaneous timelapse of 225 days from mid 2015 to early 2016).
This is the second in a series of videos made from frames I captured from a Nest cam using Google Apps Script. Music from JukeDeck.
(Published to the Fediverse as: West Portal Mosaic Timelapse #timelapse #westportal #mosaic #video Mosaic timelapse made from 225 days of footage from West Portal, San Francisco looking out over the Pacific. )


