(Published to the Fediverse as:
ISS over San Francisco #photo#iss#sanfrancisco 14 stacked two second exposures of the International Space Station (ISS) passing over San Francisco, California.)
I've been trying to put my finger on why Scot Harvath is only OK and I think it's because he's so awesome that he never really suffers from any setbacks. Everything kind of clicks into place for him and he always remembered to bring the right tactical dodad for the job. Nearly there...
Bone Silence (Revenger, #3) by Alastair Reynolds
4/5
The Revenger series comes to a close and my only regret is reading the books when published - with a sizable gap in between it can be a challenge to come back up to speed. It's a thrilling swashbuckling ride and wraps up the mystery of the quoins and the occupations. I hope he comes back to this universe at some point.
By Robert Ellison. Updated on Saturday, February 19, 2022.
Unusually good night sky conditions in San Francisco recently. Here's a video of several timelapses shot over the last couple of months. The sequences are: (super) moonrise, no Lyrids over Sutro Tower, Ursa Major rotating around Polaris, Orion setting, moonset.
The timezone database has been updated to 2020a. There is also a small fix to a problem with screensaver installation on recent versions of Windows 10.
By Robert Ellison. Updated on Saturday, February 19, 2022.
In 2020 the Summer Solstice is at 9:44pm UTC on June 20.
We get solstice from the Latin sol (sun) and sistere (to cause to stand) - the moment when the Sun stands still in its journey from north to south and back again.
Summer Solstice is the instant when the Sun is at its highest point in the sky, on the longest day of the year for the Northern hemisphere. This happens because the Earth is tilted by a little over 23 degrees (our planet rotates once a day, but relative to our orbit around the Sun the axis of rotation is at an angle). As we orbit the Sun this tilt means that different latitudes experience more or less sunlight over the course of a year. This pattern is most extreme near the poles. In the Arctic Circle the Sun never sets at the height of summer and never rises in the depth of winter. We mark two solstices each year, summer and winter. At the Summer Solstice the Sun is directly over the Tropic of Cancer (a little over 23 degrees north). We also observe two equinoxes, spring and fall (vernal and autumnal), halfway through the cycle when the Sun is directly over the Equator and a day is the same length everywhere.
The video below shows how the pattern of day and night changes over one year. You can see when the poles are completely dark or light, and the moment when the Sun 'stands still' before days start to get longer or shorter again.
Here's another perspective. This video shows a view from San Francisco made from pictures that each show a complete day (each vertical line on the picture was shot at a different time with noon at the center). You can see the length of day changing throughout the year. On less foggy days you can also see the position of sunset moving, especially with the days getting longer towards the end when San Francisco experiences less fog.
Summer Solstice isn't always on June 20th - sometimes it's June 21st or June 22nd. Irritatingly a day on your clock is not the same as a solar day and a calendar year is not the same thing as one trip around the Sun. This is why we have leap years and leap seconds to stay roughly in sync with celestial mechanics.
It's also interesting to note that Summer Solstice isn't when we're closest to the Sun or when temperatures are the highest. The Earth's orbit is elliptical and we're actually furthest away around the Summer Solstice (for now - this changes over time). Our Northern hemisphere summer is driven by sunlight hitting us directly rather than at an angle (seasons are driven by the 23 degree tilt and the position of the orbit more than our distance from the Sun). Temperatures continue to rise after the Summer Solstice mainly because it takes a while to heat up water, and so warmer weather lags the increase in direct sunlight (and vice versa as we head into colder weather after the Winter Solstice).
The exact moment of Summer Solstice pictured at the start of the post and the video of day/night over a year were created using Catfood Earth. Catfood Earth generates wallpaper from NASA Blue and Black Marble images to show the current extent of day and night combined with near real time cloud cover. Catfood Earth is totally free and available for Windows and Android.
I tried this with a solar transit last year and discovered that my expensive phone can't keep time. Learned my lesson - for this lunar transit I shot video a few minutes before and after. The video is 4K and has the unedited 1 second transit and a zoomed in slow version where you can actually see the thing. Unfortunately this means the composite at the top is made from frames extracted using ffmpeg. Next time, two cameras, so I can attempt a burst as well as a video.
(Published to the Fediverse as:
ISS Lunar Transit (4K Video) #photo#iss#moon#video 4k video of the International Space Station transiting the moon on May 7, 2020 shot from San Francisco, California)
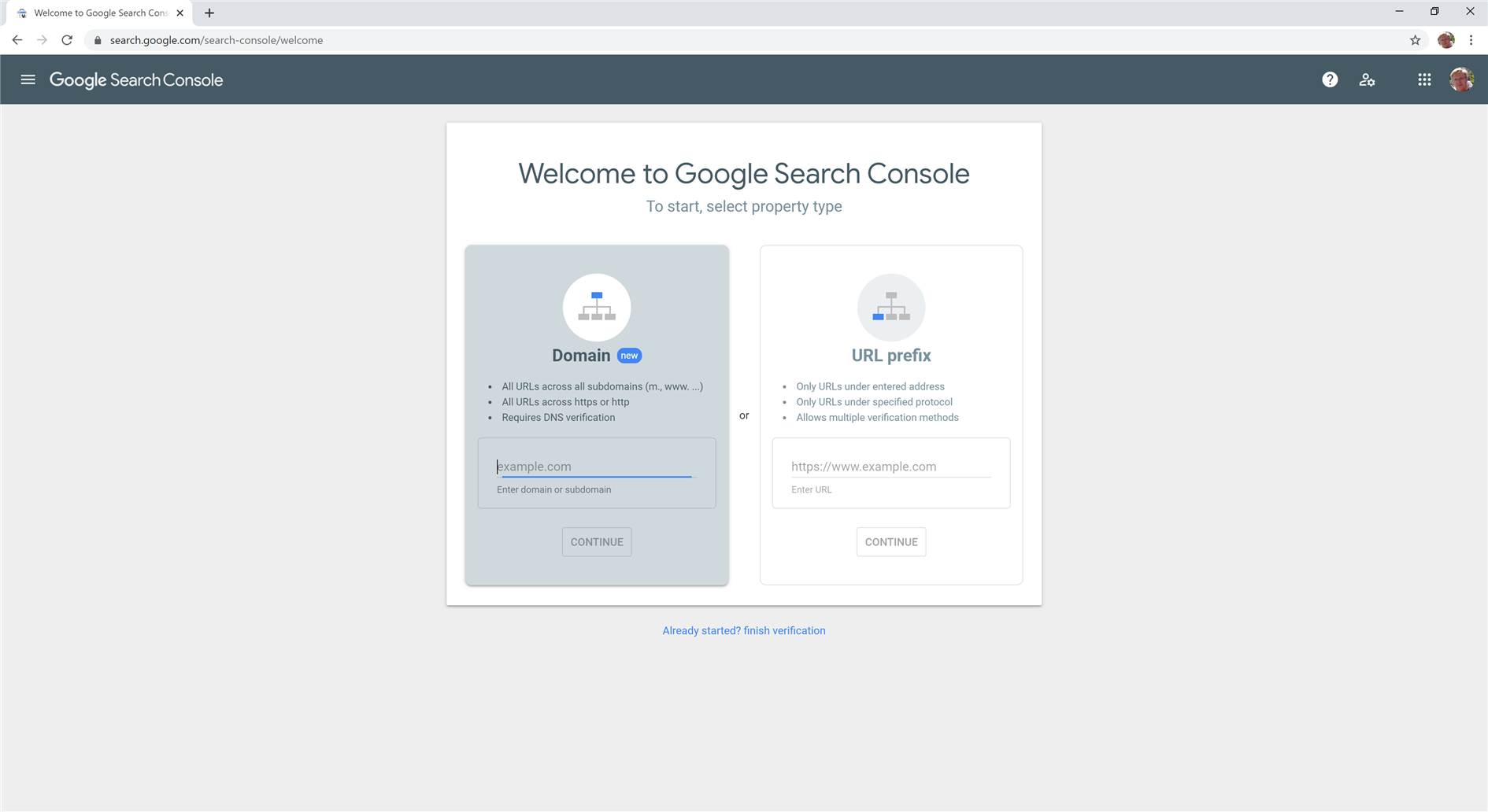
I don't know about you, but when it comes to Google Search Console I spend about 0.01% of the time adding sites and 99.99% analyzing existing ones. And yet when signing into Search Console with many verified sites the interface is ALL about adding a new one. Maybe 10% of the UX would be reasonable but it looks for all the world like I have nothing added.
To get to my sites I need to click the hamburger. Come on Google, being mobile first doesn't have to mean being desktop hostile.
Clicking the hamburger isn't even enough. This just brings up a practically blank sidebar. I then need to expand the 'Search property' drop down. Finally I get a needlessly scrolling list of my sites.
(Published to the Fediverse as:
Google search-for-your-own-verified-sites Console #etc#google#searchconsole Why do I need to click a hamburger AND drop down a menu to get to a list of verified sites in Google Search Console?)