Vernal (Spring) Equinox 2019
By Robert Ellison.
Spring starts now in the Northern Hemisphere. Rendered in (the recently updated) Catfood Earth.
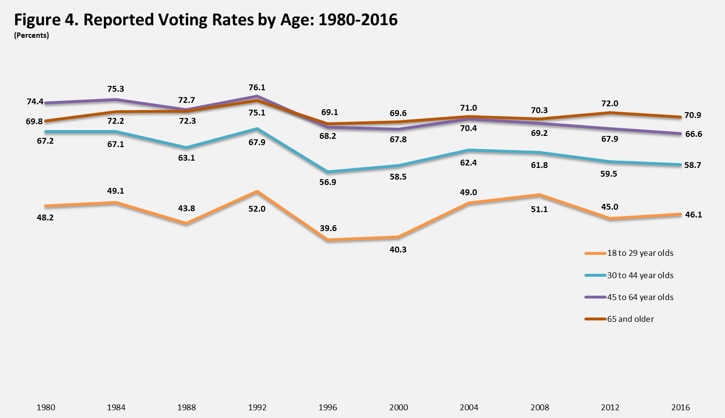
Youth turnout for elections is famously dismal. In 2016 less than half of 18-29 year-olds voted, compared to over two thirds as you get to 45 and older (US Census). The impact is an incentive to cater to the old - trying to make America great again (like you remember from when you were young) vs doing something about climate change or house prices.
One fix is compulsory voting, like in Australia. I'm not sure I want to force people without an opinion to vote though.
What if we just weighted votes by the total size of the demographic group?
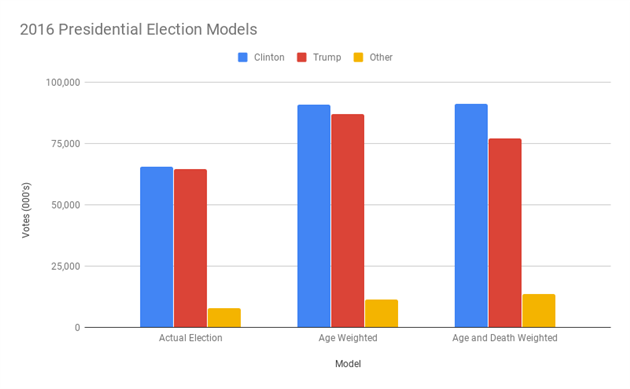
I took the demographic breakdown of 2016 voters from the US Census Bureau and multiplied these by the age breakdown from CNN exit polls. This gave Clinton a lead of just under a million votes - somewhat lower than the actual result. This is likely a polling error in the exit poll, but it's a reasonable baseline with Clinton beating Trump in the popular vote by 48% to 47%.
To age weight the result I just applied the exit poll percentages to the total population in each age bracket - i.e. what would have happened if everyone in each age group voted the same way as their peers. This obviously increases the size of the electorate so absolute numbers are less interesting. Clinton now beats Trump 48% to 46%, possibly enough to reverse the electoral college outcome (I haven't attempted this projection state by state).
Making up for poor turnout is an interesting adjustment, but what about life expectancy? All of those baby boomers have plenty of free time to vote but are not going to be around to die of obscure tropical diseases in the Minnesotan jungle. So I also weighted each population segment by life expectancy (18-29 year-olds are going to be around for another 55 years, 65+ more like 7). Clinton now has a majority instead of a plurality - she beats Trump 50% to 42%.
All three models are shown in terms of total votes counted in the chart above.
(Published to the Fediverse as: Age and Life Expectancy Weighted Voting #politics #politicalreform What if we solved the youth turnout problem by weighting election results by demographics, or to be completely fair by life expectancy as well. )
Spring starts now in the Northern Hemisphere. Rendered in (the recently updated) Catfood Earth.

Shot from the Marin headlands, the Golden Gate Overlook and near Fort Point. I used an RX10 IV with an ND3.0 filter. Raw images were captured every four seconds with a one second exposure time. Edited with LRTimelapse and scored with Filmstro Pro.
I was expecting a pretty sunny day but ended up with regular showers and some pretty wild swings between sunshine and cold soggy overcast weather. I think the occasional raindrop and the mood swings work quite well, although the wind caused a bit of wobble on the long zoom onto the deck of the bridge.
(Published to the Fediverse as: Golden Gate Bridge Timelapse #timelapse #ggb #video Time lapse of the Golden Gate Bridge shot from the Marin headlands, the Golden Gate Overlook and Fort Point in San Francisco, CA. )

Catfood Earth 3.44 is now available to download.
The timezone database has been updated to 2018i.
Eric Muller's shapefile map of timezones is no longer maintained and so Catfood Earth has switched to Evan Siroky's timezone boundary builder version.
A bug that could cause all volcanoes to be plotted at 0,0 depending on your system locale has been fixed.

3/5
Fairly droll but did not make me snort once.

5/5
Excellent sequel to 2016's Revenger. If you tried to sell this series to me - runaway sisters become fearsome space pirates while trying to figure out various mysteries about the rise and fall of a far future civilization and some truly funky currency - I'd put them someone pretty far down my to do list. But in Alastair Reynolds' hands it's a space opera masterpiece. Can't wait for the next installment.

If the atmosphere was the population of the United States...
A Tarsier.
Thomas Friedman in the New York Times today: "Could we have our first four-party election in 2020 — with candidates from the Donald Trump far right, the old G.O.P. center right, the Joe Biden center left and the Alexandria Ocasio-Cortez far left all squaring off, as the deepening divides within our two big parties simply can’t be papered over any longer?". Here's my daisyworld analogy from 2010, and a write-up of an Intelligence Squared debate on the same topic from 2011.
The scoop on Material Design 3.
Previously:
![]()
Material Design brought bland consistency to the Android ecosystem. Every app had some sort of bold header and a floating action button. There is some value in consistency and at least some personality was retained. It's red, it's probably Gmail. Yellow, I must be in Keep. Boring but tolerable.
Material Design 2 solves mainly for the problem of knowing which app you're looking at. Colors have gone. Every Google app is now an oppressive black list with some oppressive black icons. To add to the misery the icons have a shade of stock-library amateurism and are just a little too heavy. Unless I look really closely or the what-icon-did-I-just-click region of my brain is on top form there is no longer any way to tell the difference between Google apps.
I'm pretty sure Material Design 3 is just going to be a command prompt. What Android customers really want is telnet or wget and some raw JSON.
(Published to the Fediverse as: Material Design 3 #etc #google #design The slow death of personality via bland consistency that is Material Design. )



A short but steep 2.2 mile loop in San Pedro Valley Park. From the parking lot go behind the toilet block and turn right to find the start of Montara Mountain Trail. After 1.2 miles winding slowly up you reach the junction with Brooks Creek Trail at a bench with views to the Pacific. Take Brooks Creek Trail down 1 mile to the parking lot, passing another bench with a view of the waterfall on the way down.
Hike starts at: 37.578046, -122.475395. View in Google Earth.
(Hike Map)
(Published to the Fediverse as: San Pedro Valley Park Waterfall Loop #hike #sanpedrovalleypark #pacifica #map Montara Mountain Trail to Brooks Creek Trail in San Pedro Valley Park (2.2 miles, waterfall view). )


I have a 58mm ND5 filter that I bought to photograph the 2017 solar eclipse. It worked pretty well for that with my Sony RX100 V, but now I want to use it with an RX10 IV (which has the advantage of a 600mm equivalent zoom). The RX10 accepts 72mm filters and I want to try and photograph an ISS transit which is happening sooner than I can get hold of an adapter.
I figured someone must have done this before, but I can't find a file anywhere. It's a reasonably straightforward part - as the filter is smaller than the thread on the camera I just need a small cylinder which has a 72mm thread on the outside and 58mm on the inside. A step up adapter would be slightly more complicated to accommodate the larger filter size.
To build this I used OpenSCAD and this thread module. Open the thread module file in OpenSCAD and then you just need to subtract the inner thread from the outer thread like this:
This makes a simple 10mm tall adapter and you would just need to change the thread sizes to make it work for pretty much any combination of camera and filter (most filter sizes use a 0.75mm pitch as shown above). The vignetting is pretty extreme with the smaller filter and the size of the adapter. For this application I don't care, I'm only using the center of the image. If it's a problem for your application then it might be worth reducing the height of the adapter, at the expense of making it harder to detach from the camera.
Here is the adapter STL file on thingiverse.
After all that, I missed the transit by a couple of seconds. I thought the clock on my phone would be accurate enough but turns out it's 5 seconds off. So memo to self for next time - shoot over a longer window, or just take a video.
(Published to the Fediverse as: 3D Printing a 72-58mm step down Camera Filter Adapter #etc #3dprint #solar #filter #thingiverse #iss How to 3D print a step down camera filter adapter with OpenSCAD code and the STL file for a specific 72mm to 58mm project (adapting a solar filter for a Sony RX10 IV camera). )



{kind=link}