Don't show this to me again
By Robert Ellison. Updated on

HTC deserves to go bust for greying out the option to not use their sharing tool.

My company bought everyone a Fitbit for Christmas and now we're in a Battle Royale to get the most steps. I'm at a disadvantage as I often cycle to work and Fitbit does not track this accurately.
A couple of people suggested that clipping the Fitbit to your shoe would help. So over the last week I conducted an experiment. My ride from home to the office is 6.5 miles. With the Fitbit clipped into my hip pocket it registers 2,362 steps. Perched precariously on my shoe I get 2,389 steps. You can't cheat Fitbit this way.
How far off is 2,300 steps? If I was walking the same distance I'd get 13,000 steps. But I wouldn't be coasting down any hills so that isn't right either.
For my weight relaxed walking should be around 155 calories a mile, cycling at around 10 miles per hour is 78 calories a mile. This is about a 2:1 exchange rate so those 2,300 steps should be 4,600 or so.
Fitbit does have some options to manually add activities that it doesn't register correctly. This sounds too much like hard work though, it's difficult enough to remember not to put the poor device in the washing machine. I'm also 234,037 steps behind the current leader for January so I'd need to cycle home for lunch as well to stand any chance of catching up...
HTC deserves to go bust for greying out the option to not use their sharing tool.

Hulu Plus has turned out to be a bit of a disaster.
The app (I use it on a TiVo) is ugly and clumsy. I checked last night and it took 15 clicks to watch the next episode of a series I'd watched the previous night. You'd think this would be about the most basic use case and it's something that everyone else gets right.
And then it plays a couple of ads flawlessly before complaining that there is a problem with the connection. You're then bombed out to the menu and sit through the pre-roll ads again before the show starts.
I'm not stoked about being forced to watch ads on a paid service at all. If you believe the CPM estimates on Quora Hulu could charge me another $6 per month for an ad-free service that doesn't suck. Hulu ads are particularly awful because they're not embedded in the stream. This means when it's ad time everything grinds to a halt while the app switches from program mode to ad mode and then back again. You could make a cup of tea in the time it takes Hulu to figure this out. Adding insult to injury only three companies appear to have bought ads so you're stuck watching the same ones repeatedly.
All this is if the program you added to your queue still exists. Different shows seem to have different windows of availability so when you sit down to watch something you've been saving up you might find that half the episodes have been yanked away.
There is an opportunity here for a brave entrepreneur (or at least one operating somewhere with no extradition treaty with the US). What we need is an app (or service) that is the TiVo equivalent for the brave streaming cord-cutting future. You feed in the credentials for all the services you subscribe to and the programs you want to watch. The app records everything and spits out video files you can watch (and fast forward through) at your leisure.

I have an old Ambient Orb hooked up to our build server at work. It glows green when everything is working and red when a build fails. It's nice but not visible enough. My dream is to fit every developer box with a second generation blink (small USB LED indicator) or two so if things go pear shaped the whole office lights up red.

I've been using my Samsung Chromebook at work for around ten months now. It's not my main computer but it's a meeting survival powerhouse for email, instant messaging and note taking. The battery lasts approximately forever, it boots immediately and the decent keyboard and trackpad are just miles ahead of fumbling around on a tablet.
There are two problems for me with the Chrome universe. One will probably get fixed, one could be a deal breaker.
The first issue is VPN support. Apparently we use some sort of old, fiddly Cisco VPN that ChromeOS simply won't talk to. I filed Issue 261241 in the Chromium bug tracker and hopefully it will get fixed soon. If you're struggling with the same thing please star the bug report.
I can work around the VPN problem by using LogMeIn or Chrome Remote Desktop. But I can't live long without Skype. Actually I'd be perfectly happy to never use Skype again but my company runs on about fifty thousand Skype chats. I used Imo.IM for a while but they were forced to drop Skype support. Right now I'm using IM+ which as far as I'm aware is the only working Skype option for a Chromebook (please tell me if I'm wrong) but it's buggy and can't restore a connection between sessions. I either need to find a way to kill Skype at work or wait for (or write) a better web-only client.
Probably worth sticking it out, Gartner reports a 8.6% fall in PC sales but predicts Chromebooks growing to over 12 million units by 2016.
(Image by he4rtofcourage, CC).

The long bolts with plastic washers attach to the head and foot of the cot (1). These are easier to screw in using a drill with a hex bit. Put the four smallest bolts through the holes (2) before attaching the sides or you’ll be taking the sides off again. These will be used to attach the mattress spring.

Cams go in the head and foot (1), smallest bolts as described above (2).

Now just attach the sides with the medium bolts and then the mattress spring using the wing nuts.

Missing one of the medium bolts? It’s in this bag somewhere. When asking Kate to help by putting bolts in a bag remember to be very, very specific about which bag next time. The rest of the hardware is in a Ziploc in a side pocket.
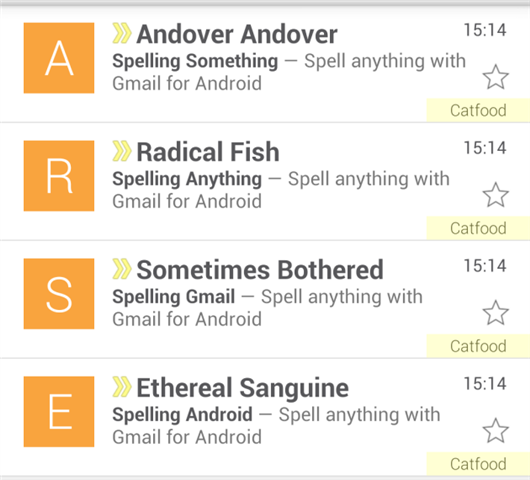
The Gmail Android client helpfully puts the first letter of the name of the person who emailed you in a big block at the left of the mail list (I guess if you have Google Plus friends you probably get a photo instead). But it's pretty easy to change the from name in your email client and trivial to do this programmatically.
Tips... spell your message backwards and use a different subject line for each email so they don't get grouped together.
I had a play with the Google Spreadsheets API recently to feed in some data from a C# application. The getting started guide is great and I was authenticated and adding dummy data in no time. But as soon as I started to work with real data I got:
"The remote server returned an error: (400) Bad Request."
And digging deeper into the response:
"We're sorry, a server error occurred. Please wait a bit and try reloading your spreadsheet."
The original sample code still worked so it didn't seem like any sort of temporary glitch as the message suggests. After much hair torn it turns out I was getting this error because I had used the literal column names from my spreadsheet. The API expects them to be lower case with spaces removed. If not columns match you get the unhelpful error above, if at least one column matches you get a successful insert with some missing data.
Error messages are one of the hardest parts of an API to get right. If you're not very detailed then what seems obvious to you can leave your developers stumped.
Hope this helps someone else...
Gmail is taking the compose window out of the corner of your window.
You know what's healthy? Leaving your house to get a snack.