By Robert Ellison. Updated on Monday, September 29, 2025.
Here are two scenarios where merged ResourceDictionary objects are the way forward.
I’m working on a WPF project that needs to be single instance. Heaven forbid that the WPF team should pollute the purity of their framework with support for this kind of thing (or NotifyIcon support but that’s another story) so I’m using the code recommended by Arik Poznanski: WPF Single Instance Application. I like this because it both enforces a single instance and provides an interface that reports the command line passed to any attempt to launch another instance.
An issue with using this code is that you need to write a Main function and so App.xaml is set to Page instead of Application Definition. Once you’ve done this the program works fine but the Visual Studio designer fails to load resources in UserControls (and in Windows containing those UserControls).
The fix is to factor all of the application level resources out into a separate ResourceDictionary (i.e. MergedResources.xaml). Once you’ve done this merge the new ResourceDictionary into App.xaml as follows:
Next, in each Window or UserControl reference the same ResourceDictionary:
The designer will now be able to find the correct resources for each UserControl and Window.
The second scenario is factoring resources and other Xaml into a DLL. To pull resources in from a referenced assembly you just need to use a Pack Uri when merging in the remote ResourceDictionary:
If you’re putting Windows and UserControls in the DLL use exactly the same approach to reference the resources using ResourceDictionary.MergedDictionaries and you’ll get designer support for these as well.
(Published to the Fediverse as:
Merging Resource Dictionaries for fun and profit #code#.net#c##wpf#xaml Get designer support for XAML loaded from a DLL by merging resource dictionaries in .NET WPF.)
By Robert Ellison. Updated on Tuesday, October 14, 2025.
WPF: When it's good it’s very, very good and when it’s bad it’s like sautéing your own eyeballs.
When you’re about to launch a process that will trigger an elevation prompt it’s polite to decorate it with the little UAC shield so the user knows what to expect. Of course there’s no such capability in WPF, and WPF controls have no handles so you can’t use SendMessage / BCM_SETSHIELD as with Windows Forms.
System.Drawing.SystemIcons.Shield seems promising, but it returns the wrong icon on Windows 7 (at least in .NET 4).
SHGetStockIconInfo will allow you to get the correct icon, but isn’t supported on Windows XP. I’ve just added the necessary interop signatures for SHGetStockIconInfo to pinvoke.net so I won’t duplicate that code here. Once you have the interop you can get the correct icon as a BitmapSource using the following code:
(Published to the Fediverse as:
UAC shield icon in WPF #code#.net#c##wpf#uac#pinvoke How to add the correct UAC shield icon for each Windows version in .NET WPF using Win32 interop.)
By Robert Ellison. Updated on Sunday, September 30, 2018.
I've written an extension for BlogEngine.NET that automatically adds several different geographical tags to blog posts. I knocked this up for my Hikes blog. It might be useful for any blog where some of the posts are related to a real world location.
To get started download GeotagFromKML.zip (2.24 kb) and copy GeotagFromKML.cs to the App_Code\Extensions folder in your BlogEngine.NET instance.
The extension does two things. Firstly it looks for a link to a KML file when post is added or updated (it does this because each of my hike posts includes a Google Earth KML file for the hike). If a KML link is found then a paragraph is added to the post containing the longitude and latitude of the first coordinate in the KML file. The paragraph uses the Geo microformat. You can customize the text in settings for the extension. You can also regenerate by deleting the paragraph and saving the post.
The second function is to add ICBM and Geo Tag META tags when serving a post that contains the geotagged coordinates. You can take advantage of this without linking to a KML file, just include a location like this in your post:
Once you have geotagging up and running you might also want to add GeoURL to the list of ping services for your site.
.NET doesn’t support rebooting, logging off or shutting down your computer though a managed API. Searching for the best way to do this brings up three options: WMI, shutdown.exe and ExitWindowsEx.
I regard WMI as the last resort of the desperate. Weakly typed magic string juju.
Calling Process.Start(“shutdown.exe /r /t 0”) might work, but how would you know? And you’ve got the overheard of starting a new process just to accomplish a reboot. Lazy.
The best way to reboot is P/Invoke to ExitWindowsEx. Unfortunately there’s some really awful sample code out there which will either fail to do anything or mask any errors. I’ve included a drop-in class below that fixes these problems.
If you read all the way through the documentation for ExitWindowsEx you’ll find this:
To shut down or restart the system, the calling process must use the AdjustTokenPrivileges function to enable the SE_SHUTDOWN_NAME privilege. For more information, see Running with Special Privileges.
So just calling ExitWindowsEx won’t do anything. The sample code below adjusts the process token and then reboots (change the flags passed to ExitWindowsEx to shutdown instead, or to pass in a different reason). You’ll also get a Win32Exception if a failure occurs. Catch this, and you can tell the user that they need to reboot manually.
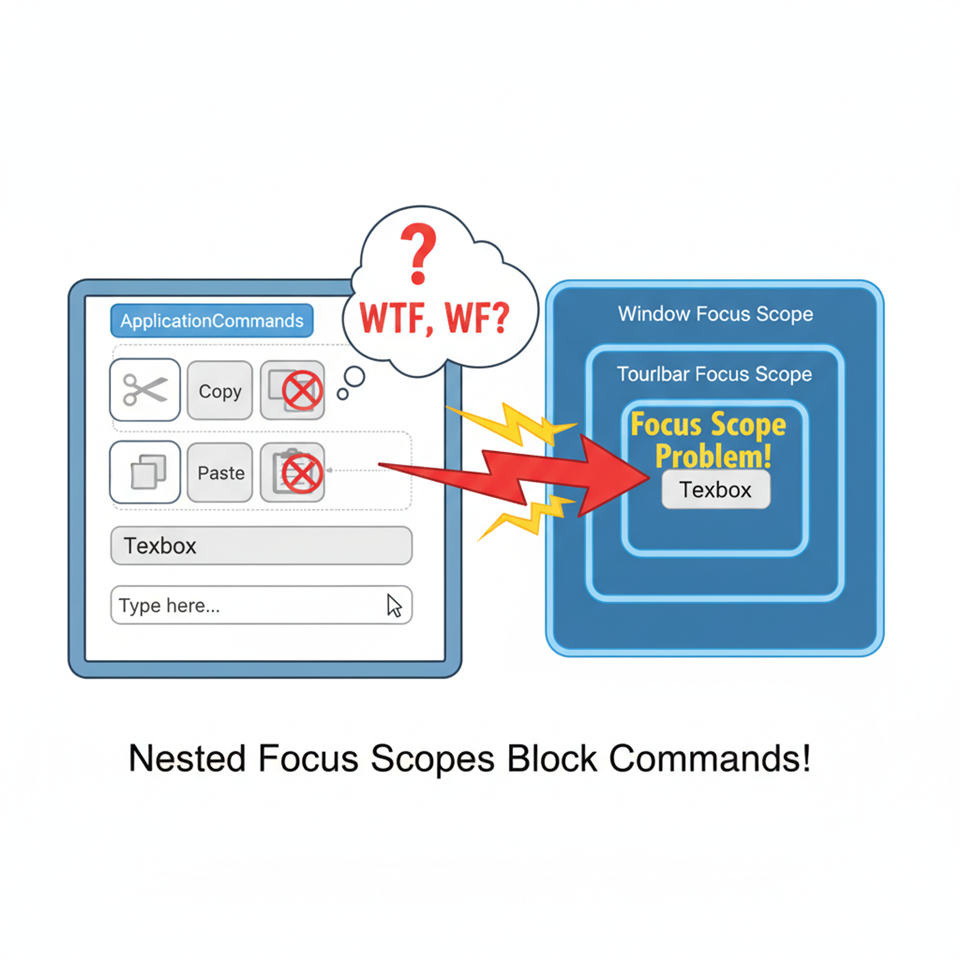
Here's a frustrating WPF scenario — you use the ApplicationCommands class to add Cut, Copy and Paste commands to toolbar and then put a TextBox on another toolbar. Click in the TextBox and the commands remain disabled. WTF, WPF?
The problem is with focus scopes. Your window is a focus scope and so are any menus or toolbars. This has the desirable property of allowing commands to target the control you were in immediately before invoking the command. You want paste to target the text box you're editing, not the menu item or button you clicked to request the paste.
So far so good. The problem is that the commanding system isn't smart enough to target the control with keyboard focus if it's in a nested focus scope. Remember that the window itself is a focus scope so our TextBox in a ToolBar (also a focus scope) is nested and immune to commands from our menu or toolbar.
Here's a simple window that demonstrates the problem:
Ignore the PreviewCanExecute handler for now. If you run this window and click in the main TextBox the paste button and menu item are enabled. Click in the toolbar TextBox and pasting isn't an option. Well, Ctrl-V still works and there's a context menu but you know what I mean.
The problem can be fixed by adding a command binding for ApplicationCommands.Paste and handling the PreviewCanExecute event:
When the window loads we're making note of the focus scopes for the toolbar and menu. Then when PreviewCanExecute fires we check to see if the element with the keyboard focus is in a different focus scope (and also that the window doesn't have keyboard focus). We then set the CommandTarget for the menu item and button to the element that has keyboard focus.
A handler isn't required for CanExecute as the command will take care of this with respect to the new CommandTarget.
Run the window again and you'll see that the paste button is enabled for both of the TextBox controls. When you click the button (or menu item) our PreviewCanExecute handler ignores the new keyboard focus and the command is sent to the desired control.
One drawback of this approach is that keyboard focus isn't returned to the TextBox after the command executes. The CommandTarget remains in place so you can keep pasting and the command remains enabled but you lose the visual cue that lets you know where the target is. I haven't figured out a clean approach to this yet. When I do, I'll update this post. Better yet, if you've figured it out leave a comment.
(Published to the Fediverse as:
WPF commands with nested focus scope #code#wpf#.net#c##xaml How to persuade a WPF application to paste into a selected control when the control is in a different focus scope.)
I'm slowly converting a number of blogs from Blogger to BlogEngine.NET. The least fun part is dealing with the Blogger export file. For this blog I used a Powershell script but had problems with comments not exporting correctly and it was quite painful to fix everything up. Blogger allows you to export a copy of your blog using ATOM, however BlogEngine.NET (and other tools) speak BlogML.
I've just released a command line tool that takes the ATOM format Blogger export and converts it to BlogML. You can download Blogger2BlogML from GitHub. The tool uses .NET 4.0 (client profile) so you'll need to install this if you don't already have it. If you give Blogger2BlogML a try let me know how you get on.
(Published to the Fediverse as:
Converting Blogger ATOM export to BlogML #code#blogger#blogml#codeplex#c##.net Tool that converts Blogger ATOM blog export files to BlogML for importing to a different blog engines.)
I've just released a small update for my ESRI Shapefile Reader project on GitHub. The only change is a patch from SolutionMania that fixes a problem when the shapefile name is also a reserved name in the metadata database. The patch escapes the name preventing an exception from being thrown.
Catfood.Shapefile.dll is a .NET 2.0 forward only parser for reading an ESRI Shapefile. Download 1.20 from GitHub.
The Volume Shadow Copy Service (VSS) takes a snapshot of an NTFS drive at a point in time. The clever thing about VSS is that it doesn't copy anything — it starts with the assumption that nothing has changed and then keeps track of every change to the snapshot so only changes need to be stored.
From Windows Vista on it's possible to mount a shadow copy as a drive letter or share. ShadowTask is a command line tool that creates a VSS copy, mounts it as a drive and then runs a program or batch file. For example:
ShadowTask C V dostuff.bat
Creates a copy of C:, mounts it as V: and then runs dostuff.bat.
Let's say you want to copy a locked file — maybe some outlook personal folders. Dostuff.bat could contain:
The ZIP contains both 32 and 64 bit versions of the tool. You must use the version that matches your platform. ShadowTask supports Windows Vista and 7. XP doesn't support mounting a shadow copy so ShadowCopy will fail if you try to use it on XP. ShadowCopy must run as admin (elevated).
(Published to the Fediverse as:
Do useful things with the volume shadow copy service (VSS) #code#vss ShadowTask mounts a volume shadow copy to a drive letter using VSS and then lets you run a batch file (maybe to copy a locked file or backup the entire drive))
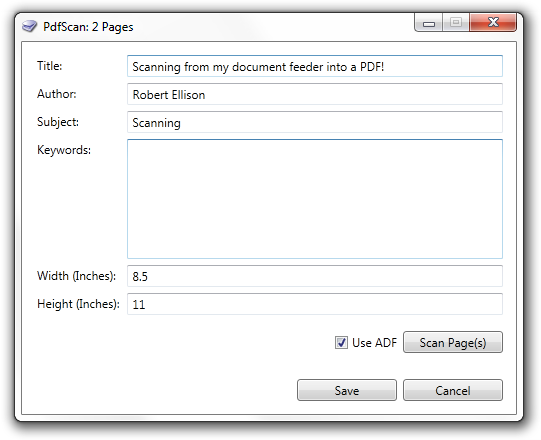
PdfScan is a simple tool for scanning pages into a PDF file. You can scan single pages from a flatbed scanner or several pages from a document feeder. The page size applies to both the scan and the page(s) added to the PDF.
I wrote PdfScan because I know I'm going to be scanning a lot of documents over the next couple of weeks. Previously I used a tool called ScanToPDF from O Imaging but their licensing pissed me off so much that I'd rather waste time reinventing the wheel than pay them for another copy.
This is a beta — it works with my scanner and my documents. There's no installer, so extract the ZIP file and run the EXE to use it. PdfScan requires the .NET 4.0 Framework. If you get an error when you run PdfScan.exe try installing .NET 4 and then run it again.
If enough people use this I'll make it a bit more friendly, add an installer and release it through Catfood. If you like it leave a comment below. If it doesn't work for you leave a comment or email me and I'll try to help.
(Update September 12, 2010: I've tided PdfScan up and released it through Catfood Software. Download from Catfood PdfScan.)
I've been going nuts trying to scan from the document feeder on my Canon imageClass MF4150. Everything worked as expected from the flatbed, no dice trying to persuade the ADF to kick in. I found some sample code but it was oriented towards devices that can detect when a document is available in the feeder. Evidently my Canon doesn't expose this and so needs to be told the source to use.
The way to do this is to set the WIA_DPS_DOCUMENT_HANDLING_SELECT property to FEEDER. You then read WIA_DPS_DOCUMENT_HANDLING_STATUS to check that it's in the right mode and initiate the scan. This did not work for toffee.
After much experimentation I discovered a solution. I had been setting device properties and then setting item properties before requesting the scan. Switching the order - item then device - made everything work.
Here's the function to scan one page:
A few notes — XImage is a type from PDFSharp. I wrote this as part of a PDF scanner that I'll post next so the scanned images are saved and then loaded into an XImage for rendering to the PDF document. The magic numbers come from WiaDef.h in the Platform SDK. If the ADF is out of pages this method sets the return image to null and eats the exception. This is because the function is called repeatedly to scan in pages until the ADF is empty if _adf is true (otherwise it grabs one image from the flatbed).
If you've been banging your head against a wall trying to get WIA to work with a document feeder I hope this helps.
PdfScan is a simple tool for scanning pages into a PDF file. You can scan single pages from a flatbed scanner or several pages from a document feeder. The page size applies to both the scan and the page(s) added to the PDF.
I wrote PdfScan because I know I'm going to be scanning a lot of documents over the next couple of weeks. Previously I used a tool called ScanToPDF from O Imaging but their licensing pissed me off so much that I'd rather waste time reinventing the wheel than pay them for another copy.
This is a beta — it works with my scanner and my documents. There's no installer, so extract the ZIP file and run the EXE to use it. PdfScan requires the .NET 4.0 Framework. If you get an error when you run PdfScan.exe try installing .NET 4 and then run it again.
If enough people use this I'll make it a bit more friendly, add an installer and release it through Catfood. If you like it leave a comment below. If it doesn't work for you leave a comment or email me and I'll try to help.
(Update September 12, 2010: I've tided PdfScan up and released it through Catfood Software. Download from Catfood PdfScan.)
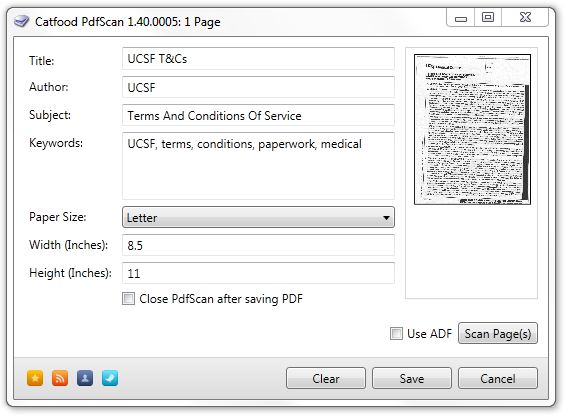
Catfood PdfScan 1.40 is a small bug fix release. PdfScan converts documents to PDFs with the help of a flatbed or automatic document feeder (ADF) scanner.