Nope: "To unlock the device with a passcode, hold out your hand to project a green laser onto your palm. Pulling your hand outward increases the number while pulling it inward decreases it, and you select each digit by pinching two fingers on the same hand." #ml#humane
“The system is currently working just fine, but we know that with each increasing year, risk of data degradation on the floppy disks increases and that at some point there will be a catastrophic failure,” - maybe save $400M with a floppy emulator and a USB stick? #sfmta#muni#sanfrancisco
Download a Sharepoint File with GraphServiceClient (Microsoft Graph API) #code#ml#graph#sharepoint#c# Everyone developing applications with the Graph API should know about the shares endpoint that allows you to download files easily.
There is a stunningly simple way to get a file out of sharepoint and I'll get to that soon (or just skip to the very end of the post).
I have been automating the shit out of a lot of routine work in Microsoft Teams recently. Teams is the result of Skype and Sharepoint having too much to drink at the Microsoft holiday party. It often shows. One annoyance is that channel threads are ordered by the time that someone last responded. Useful for quickly seeing the latest gossip but a pain when you need to keep an eye on each individual thread. After listlessly scrolling around trying to keep up with the flow I came up with a dumb solution - I sync the channel to Obsidian (my choice of note app, could be anything) and then I can just check there for new threads. It's a small convenience but has meaningully improved my life.
Unfortunately I got greedy. These messages usually have a PowerPoint presentation attached to them and so why not have an LLM summarize this while updating my notes?
It doesn't look like Copilot has a useful API yet. You can build plug-ins, but I don't want to talk to Copilot about presentations, I just want it to do the heavy lifting while I sleep so I can read the summary in the morning. Hopefully in the future there will be a simple way to say hey, Copilot, summarize this PPTX. Not yet.
So the outline of a solution here is download the presentation, send it ChatGPT, generate a summary and stick that in Obsidian. This felt like a half hour type of project. And it should have been - getting GPT4 Turbo to summarize a PPTX file took about ten minutes. Downloading the file has taken days and sent my self esteem back to primary school.
You would think that downloading a file would be the Graph API's bread and butter. Especially as I have a ChatMessage from the channel that includes attachments and links. The link is for a logged in human, but it must be easy to translate from this to an API call, right?
It turns out that all you need is the site ID, the drive ID and the item ID.
These IDs are not in the attachment URL or the ChatMessageAttachment. It would be pretty RESTful to include the obvious next resource I'm going to need in that return type. No dice though.
I tried ChatGPT which helpfully suggested API calls that looked really plausible and helpful but that did not in fact exist. So I then read probably hundreds of blogs and forum posts from equally confused and desperate developers. Here is a typical example:
"Now how can I upload and download files to this library with the help of Graph API (GraphServiceClient)."
To which Microsoft, terrifyingly, reply:
"We are currently looking into this issue and will give you an update as soon as possible."
Ignoring the sharepoint part and glossing over where that drive ID is coming from. Other documentation suggests that you can lookup your site by the URL, and then download a list of drives to go looking for the right one. Well, the first page in paginated drive collection anyway implying that just finding the ID might get you a call from the quota police.
I know Microsoft is looking after a lot of files for a lot of organizations, but how can it be this hard?
It isn't. It's just hidden. I eventually found this post from Alex Terentiev that points out that you just need to base64 encode the sharing url, swap some characters around and then call:
If Google was doing its job right this would be the top result. I should be grateful they're still serving results at all and not just telling me that my pastimes are all harmful.
The documentation is here and Microsoft should link to it on every page that discusses drives and DriveItems. For GraphServiceClient the call to get to an actual stream is:
(Published to the Fediverse as:
Download a Sharepoint File with GraphServiceClient (Microsoft Graph API) #code#ml#graph#sharepoint#c# Everyone developing applications with the Graph API should know about the shares endpoint that allows you to download files easily.)
Rob 2.0 #code#openai#ml#agi An AI version of Robert Ellison. You can ask questions by leaving a comment.
Updated on Friday, April 5, 2024
If I'm going to be replaced with AI then I may as well be the person to do it. I need an AI Rob that I can be proud of and that's going to take some work.
My approach so far is to generate some training data. I've answered lots of questions in a spreadsheet. This is an ongoing project and there will be dot releases as I work towards a usable product (one that I can just plug into email or Teams). Probably this is going to require a mix of fine tuning and retrieval augmented generation (RAG). To start with I'm just fine tuning GPT 3.5 Turbo from OpenAI.
Fine tuning was painless. As usual the difficult part was randomly trying different versions of Python to find one that would coexist with some stubborn dependency (tiktoken in this case, which will live with Python 3.11 but is very unhappy with Python 3.12).
You can try this below - just leave a comment and Rob 2.0 will reply. Anything you post goes through the regular moderation system, this is just to stop spam. any legitimate questions are fair game (and likely to make it into the training corpus if the answer is no good!).
Due to safety systems it doesn't swear like the real thing. That might require a different model / corporate host at some point in the future. I'll update this post as I make progress.
Updated 2023-12-20 00:46:
I had most of a day spare today and so decided to get a little closer to my own personal singularity. Rob 2.1 is live and answering your questions in the comments below.
The first thing I did was add a few hundred more questions and answers to my training data set. I then fine tuned GPT 3.5 on the new data.
I wanted to get the LLM trinity - prompt, retrieval augmented generation (RAG) and fine turing. Initially I thought that I could just use the OpenAI assistant API to get there, and I got as far as coding the whole thing up before stubbing my toe on a harsh reality. It only supports retrieval for gpt-3.5-turbo-1106 and gpt-4-1106-preview. Hopefully this changes at some point but no way to get everything I need from assistants yet.
Not a big deal - I rolled up my sleeves (and also GitHub Copilot's sleeves) and added my own RAG based on the Q&A training data and refined my prompt to include the most relevant answer as well as some more specific instructions. It's pretty basic - whatever you ask is compared to the existing question library using cosine distance of OpenAI embeddings. Maybe I'll add a vector database if I have the patience to answer enough questions about myself, but a brute force in memory search works fine for now.
It usually takes me a few weeks to get a new website up and running. Last weekend I tried an experiment with Cloudflare Pages and generative AI.
I have wanted to find an excuse to test Pages for a while. It's a pretty awesome product. I'm not doing anything too fancy with it - I have a local generator app that creates the pages for my site. Committing to the right branch in git automatically deploys to Cloudflare's edge network. It seems to do the right thing with all the file types I've thrown at it so far. My only complaint at this point is that it doesn't handle subdirectories. Everything needs to hang off the root unless you want to write some code. I think this is possible with Cloudflare Workers but that's for another day.
The generative piece is automatically writing content for review and publication. For each generated page I'm creating a prompt to write the post, and then another prompt to summarize it for meta descriptions and referencing it from other pages. I also create an embedding to use for interlinking related posts. Finally I create a third prompt to gin up an appropriate image. The site generator stitches these together into HTML and as soon as I commit, the updates are live.
The site is not yet a work of art, and there is plenty to optimize and add, but the basic thing was working in a few hours. It's all ridiculously cheap as well. I'm more than a little frightened for Google given how much of this must be going on right now. And then the next generation of LLMs will be trained on the garbage produced by the current crop.
My super rapid site is called Shop Stories, collecting / dreaming takes of ecommerce heroics. I'll report back if anyone goes there.
Predicting when fog will flow through the Golden Gate using ML.NET #code#video#ml#fog Using Microsoft's AutoML in ML.NET to build an image classifier that predicts fog flowing under the Golden Gate Bridge.
I'd like to make a time lapse of the moment when fog enters the Golden Gate and flows under the Golden Gate Bridge. It's surprisingly hard to know when conditions will be just right though. Often the weather is pleasant at my house while the fog is sneaking through and there is very little chance of me checking a webcam or satellite image. I decided to fix this about a year ago and started collecting data. The best bet seemed to be GOES-West CONUS - Band 2 which is a high resolution daylight satellite image that shows clouds and fog. I put together a Google Apps Script project to save an hourly snapshot and left if running. Here's a video of the data so far, zoomed in for a HD aspect ratio and scaled up a bit:
It's pretty obvious to me when conditions are just right. Could an ML model learn that this was about to happen from an image that was three hours older?
The first step was dividing thousands of images into two classes - frames where the fog would be perfect in three hours and frames where this was not going to happen. I built a little WPF tool to label the data (I don't use this often these days and every time I do I marvel at how the Image control has defaults that won't show the image FFS). This had the potential to be tedious so I built in some heuristics to flag likely candidates and then knocked out the false positives. Because the satellite images include clouds there is often white in the Golden Gate that is cloud cover rather than fog. At the end of the process I had two subfolders full of images to work with.
My goal this weekend was to get something working, and then refine every few months as I get more data. Right now I have 18 images that are in the Fog class and 7,539 that are NoFog. I also wanted this running on my blog, which is .NET 4.8 and will stay that way until I get a couple of weeks of forced bed rest. ML.NET says that it's based on .NET Standard and so should run anywhere.
Having local automl is very cool once you get it working. For large datasets this might not be a great option, but not having to wrangle with the cloud was also very appealing for this project.
Getting GPU training configured involved many gigabytes of installs. Get the latest Visual Studio 2022. Get the latest ML.NET model builder. Sign up for an NVIDIA developer account and install terrifyingly old and specific versions of CUDA and cuDNN. This last part was the worst because the CUDA installer wanted to downgrade my graphics driver, warned directly that this would cause problems and then claimed that it couldn't find a supported version of Visual Studio. I nervously unchecked everything that was already installed, and so far model builder has run fine and I don't seem to have caused any driver problems.
For image classification settings you can choose micro-accuracy (the default), macro-accuracy, logarithmic loss, or logarithmic loss reduction. Micro-accuracy is based on the contribution of all classes and unsurprisingly it's useless in this case as just predicting 'no' works very well overall. Maco-accuracy is the average of the accuracy of each class and this produced reasonable results for me. Possibly too good, I probably have some overfitting and will spend some time on that soon.
After training the model builder has an evaluate tab which is pretty worthless, at least for this model/case. You can spot check the prediction for specific images, and then there is one overall number for the performance of the model. I'm used to looking at precision and recall and it looks like I'll have to spend some time building separate tooling to do this. Hopefully this will improve in future versions.
At this point I have a .NET 6 console application that can make plausible looking predictions. Overall I'm very impressed with how easy it was to get this far.
Integrating with my blog though was very sad. After a lot of NuGet'ing and Googling I came to realize that ML.NET will not play nice with .NET 4.8, at least for image classification. Having dared to anger the NuGet gods I did a git reset --hard and called out to a new .NET 6 process to handle the classification. For my application I'm only running the prediction once per hour so I'm not bothered by performance. That .NET Standard claim proved to be unhelpful and I could have used just about anything.
The model is now running hourly. I have put up a dedicated page, Golden Gate Fog Prediction, with the latest forecast and plan to improve this over time. If this would be a useful tool for you please leave a comment below (right now it emails me when there is a positive prediction, it could potentially email a list of people).
Updated 2023-03-12 23:24:
After building some tooling to quantify this first model I have some hard metrics to add. Precision is 23%. This means there is a high rate of false positives. Recall is 78%. This means that when there really is fog the model does a pretty good job of predicting it. Overall the f1 score is 35% which is not great. In practice the model doesn't miss the condition I'm trying to detect often but it will send you out only to be disappointed most of the time. I'm not that surprised given how few positive cases I had to work with so far. My next steps are collecting more training data and looking more carefully at the labeling process to make sure I'm not missing some reasonable positive cases.
(Published to the Fediverse as:
Predicting when fog will flow through the Golden Gate using ML.NET #code#video#ml#fog Using Microsoft's AutoML in ML.NET to build an image classifier that predicts fog flowing under the Golden Gate Bridge.)
OpenAGI, or why we shouldn't trust Open AI to protect us from the Singularity #etc#openai#ml What OpenAI got wrong in their blog post on AGI and how we should treat AGIs if they ever arrive.
Open AI just dropped a pretty remarkable blog post on their roadmap for not destroying civilization with their imminent artificial general intelligence (AGI):
"As our systems get closer to AGI, we are becoming increasingly cautious with the creation and deployment of our models. Our decisions will require much more caution than society usually applies to new technologies, and more caution than many users would like."
Now, I'm around 98% sure that Open AI mostly answers the question: What if we allocated unlimited resources to building a better auto-complete? ChatGPT is an amazing tool but it's amazing at guessing which word (token) is likely to appear next. Quite possibly their blog post is just an exercise in anchoring - if they're 95% of the way to AGI then GPT4 must be pretty amazing and therefore worth a lot of money. If everyone realized that they're more like 2% of the way there, and the next 1% is going to be exponentially difficult, then some of the froth would blow off.
Their ideas for keeping us safe are a little disturbing:
"We think public standards about when an AGI effort should stop a training run, decide a model is safe to release, or pull a model from production use are important."
Given the lack of transparency around the inner workings of ML models, and the lack of knowledge around what intelligence even looks like, this is a pretty risible idea. And:
"Finally, we think it’s important that major world governments have insight about training runs above a certain scale."
We are facing down the prospect of a second Trump term while the UK has a Prime Minister who thinks that a homeless person might be 'in business'.
The most concerning part for me is:
"...we hope for a global conversation about three key questions: how to govern these systems, how to fairly distribute the benefits they generate, and how to fairly share access."
Creating AGI would be an amazing and terrifying accomplishment. Treating it as a slave feels like the most surefire way to usher in the most terrifying possible consequences, for us and for the AGIs.
Full disclosure: I use Open AI embeddings for related posts and site search. The words on this blog are my own though. I do occasionally generate a post image using Stable Diffusion like the rather strange one above.
(Published to the Fediverse as:
OpenAGI, or why we shouldn't trust Open AI to protect us from the Singularity #etc#openai#ml What OpenAI got wrong in their blog post on AGI and how we should treat AGIs if they ever arrive.)
Upgrading from word2vec to OpenAI #code#ml#openai#ithcwy#word2vec Using the Open AI embeddings API to find better related posts for a blog.
In 2018 I upgraded the related posts functionality on this blog to use word2vec. This was hacked together by averaging the vectors for interesting words in each post together and then looking for the closest vectors. It worked quite well, but the state of the art has moved on just a little bit since then.
OpenAI has an embeddings API and recently released a cheaper model called text-embedding-ada-002. The vectors have 1,536 dimensions, a pretty significant increase from the 300 I was using with word2vec. Creating vectors for all my posts took a few minutes and cost $0.11 which is pretty affordable. As you'd expect those related posts are now significantly more related and useful. Thanks OpenAI!
I shared some code previously for the word2vec hack. This is a lot more straightforward - call the API with the post text and then compare the vectors with cosine distance to find the most related. It works well for search too.
(Published to the Fediverse as:
Upgrading from word2vec to OpenAI #code#ml#openai#ithcwy#word2vec Using the Open AI embeddings API to find better related posts for a blog.)
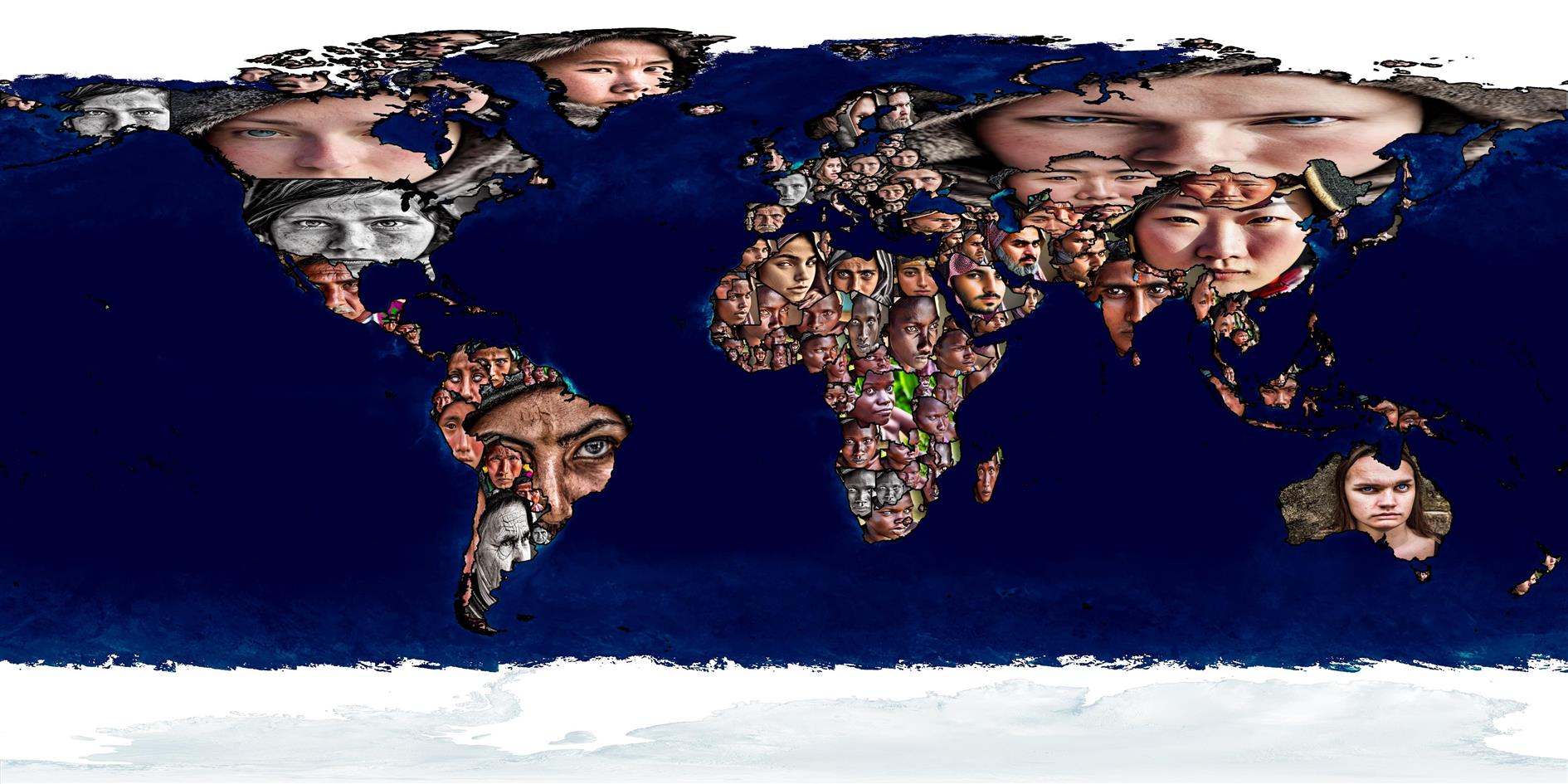
Stable Diffusion Global Stereotypes #etc#ml#stablediffusion A composite image of 248 faces generated by Stable Diffusion for each country in the world.
What does Stable Diffusion think a typical person looks like from each country?
This image is composed of 248 faces generated with the following prompt:
"photo of a typical person from Vietnam, highly symmetrical face, portrait photography, highly detailed Vietnam background, 4k, 35mm, sharp focus, amazing photo, portrait of the year"
Using seed 960604, 50 iterations, 7.5 scale, and just varying the country name in the prompt text.
There is no gender implied in the prompt but it certainly seems more likely to generate a woman. It seems to find something distinctive about most countries. The region that surprises me the most is Eastern Europe which ends up being very similar. Click the image above for a larger version.
(Published to the Fediverse as:
Stable Diffusion Global Stereotypes #etc#ml#stablediffusion A composite image of 248 faces generated by Stable Diffusion for each country in the world.)
Stable Diffusion Watches a Security Camera - a short horror movie #etc#video#stablediffusion#ml#4k#animation A horror movie created by forcing Stable Diffusion to watch a random Japanese security camera for 24 hours.
Updated on Friday, September 16, 2022
A horror movie made by forcing img2img to watch a Japanese security camera over 24 hours.
The office was empty, so the main influences are sunrise and sunset and then just subtle shifts in lighting. In terms of settings, strength was 0.75 with scale of 6.6 so the animation doesn't look anything like the actual office in question. The prompt was "photo of something unspeakable lurks in the shadows of the office, high quality, cinematic lighting, subtle horror, horrifying, japanese, found footage, sharp focus, 8k, no text". I upscaled with Gigapixel AI and then added some music.
(Published to the Fediverse as:
Stable Diffusion Watches a Security Camera - a short horror movie #etc#video#stablediffusion#ml#4k#animation A horror movie created by forcing Stable Diffusion to watch a random Japanese security camera for 24 hours.)
A black lab chases a Roomba and then things start to get weird... #etc#video#animation#stablediffusion#4k#ml Stable Diffusion img2img generated from a video of a dog chasing a Roomba.
Another experiment with Stable Diffusion (see my San Francisco skyline video from earlier today). This one uses img2img instead of txt2img. I started with a video of my dog following the Roomba around the house. I dumped all the frames out and then used Stable Diffusion with the strength parameter ramping up from 0.0 (source image preserved) to 1.0 (source image ignored) and a scale of 11.5. The prompt was "illustration of a black labrador being chased by a giant scary roomba trending on deviant art". The frame at the top maybe best captures this concept. I used Gigapixel AI to scale the output back up to 4K resolution and then added the original soundtrack.
(Published to the Fediverse as:
A black lab chases a Roomba and then things start to get weird... #etc#video#animation#stablediffusion#4k#ml Stable Diffusion img2img generated from a video of a dog chasing a Roomba.)




![[1536]](/image.axd?picture=1536.png)